Tässä pilotissa tehtiin katsaus syvään vahvistusoppimiseen (deep reinforcement learning) ja sen viimeisimpiin algoritmeihin ja arvioitiin näitä algoritmeja erilaisissa realistisissa tekniikan sovelluksissa.
Vahvistusoppiminen on koneoppimisen suuntaus, jossa sovellusagentit, jotka sisältävät tekoälyn, ja laitteet automaattisesti tunnistavat ideaalin toimintatavan tietyssä tilanteessa, tehden jatkuvasti arvoperusteista arviointia valitakseen tilanteeseen sopivimmat ratkaisut huonojen ratkaisujen sijaan. Vahvistusoppiminen perustuu kokeilu- ja virheoppimiseen tarkan mallinnuksen sijasta, luodakseen tehokkaan ohjaimen, vaikka tarkkoja malleja ei olisi saatavana. Vahvistusoppimisen kolme päämenetelmää ovat: arvopohjainen, toimintatapapohjainen ja mallipohjainen.
Syväoppimista hyödynnettiin vahvistusoppimisessa. Vahvistusoppimisalgoritmit vaativat sekä arvon että toimintatavan olevan arvotettu ympäristön kanssa vuorovaikutuksessa kerätyn näytteen perusteella. Tämä arvotusongelma ratkaistiin esittämällä nämä toiminnot syvien monikerroksisten neuroverkkojen muodossa. Syvä neuroverkko koostuu useista kerroksista epälineaarisia prosessointiyksiköitä.
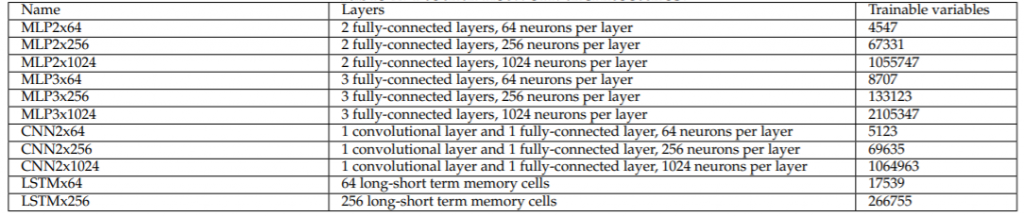
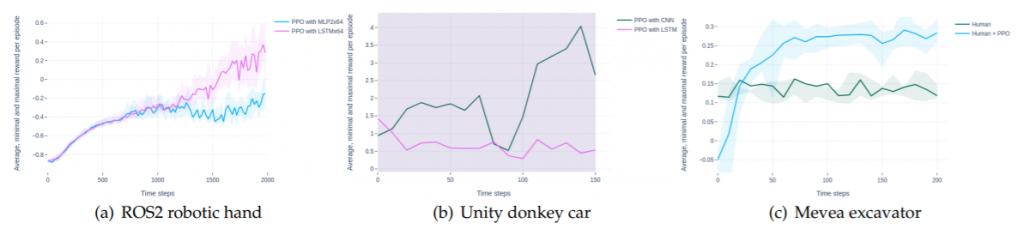
Pilotissa käytettiin DDPG-, tavallista A2C- ja PPO-algoritmeja, joissa käytetään erilaisia neuroverkkoarkkitehtuureja toimintatapa- ja arvofunktioiden arviointiin, tekoälyn kouluttamiseksi ohjaamaan konetta simuloidussa ympäristössä, jossa sekä tila että toiminnot ovat jatkuvia.

Tarkempaa tietoa tästä aiheesta löytyy englanniksi raportista.
Liittyvät raportit ja julkaisut:
03.06. Raportit
2020 Reinforcement_Learning_in_Engineering_Applications (pdf)